
O que é a Engenharia do Caos?#
De maneira resumida a Engenharia do Caos ou do inglês Chaos Engineering é a disciplina de realizar experimentos sobre sistemas com o intuito de construir confiança com relação a capacidade de um sistema suportar condições adversas em produção.
Vantagens#
Detecção de falhas ocultas:#
Testes de caos ajudam a descobrir problemas que só se manifestam em condições adversas ou em eventos de falha, muitas vezes não detectáveis em ambientes de testes tradicionais.
Aumento da resiliência:#
Ao simular falhas inesperadas (como quedas de pods, falhas de rede, ou perda de conexão com bancos de dados), os mecanismos de caos permitem que as equipes identifiquem pontos fracos na arquitetura e ajustem os serviços para se recuperarem rapidamente de problemas.
Validação de políticas de autorrecuperação:#
No Kubernetes existem várias ferramentas de autorrecuperação, como replication controllers e self-healing. A aplicação de engenharia do caos verifica se esses mecanismos funcionam corretamente quando expostos a falhas.
Preparação para cenários do mundo real:#
Em produção, as falhas são inevitáveis. O teste de caos colocam a infraestrutura sob estresse para simular cenários como picos de tráfego, interrupções parciais de rede ou queda de nós. Isso ajuda a preparar a equipe para lidar com situações reais de forma mais proativa.
Garantia de disponibilidade contínua:#
Muitos sistemas distribuídos são projetados para alta disponibilidade. A engenharia do caos valida se o sistema mantém a disponibilidade e funcionalidade mesmo durante eventos disruptivos, alinhando-se aos requisitos de SLAs.
Automatização de testes de resiliência:#
Com ferramentas como Chaos Mesh ou LitmusChaos, é possível automatizar a execução de experimentos de caos no Kubernetes, permitindo testes contínuos que acompanham a evolução da arquitetura e infraestrutura.
Possíveis pontos de falha que podem ser testados#
- Rede,
- Falha de pod,
- Falha de nó,
- Alta carga de CPU,
- Alta carga de memória,
- Falhas de implantação,
- Testar autoscaling,
- Falha ao inicializar container,
- Falhas de dependência.
Como implementar (Teoria)#
Apesar do nome fazer referência ao caos, os testes precisam ser organizados e planejados para que se consiga gerar bons resultados e métricas. Alguns pontos importantes sobre os passos que precisamos seguir para aplicar um teste de engenharia do caos:
Conhecer o estado: Antes de mais nada é importante conhecer o estado atual do recurso a ser testado, quanto de CPU ou memória os sistemas usam geralmente, qual a latência média, etc.
Criar hipóteses: Aqui podemos também responder algumas questões como, por exemplo, o que acontece se um serviço cair ou a latência estiver muito alta. Criamos algumas perguntas para serem respondidas durante os testes.
Escolha das ferramentas: Diversas ferramentas podem ser utilizadas inclusive scripts, intervenção manual ou ferramentas especificas de engenharia do caos.
Configurar experimento: Baseado no objetivo criamos experimentos que vão executar ações definidas, aumentar latência, simular quedas de pod, aumentar estresse dos recursos, etc.
Observar comportamento: Aqui iremos analisar o impacto dos testes, tanto nos serviços alvos quanto em outros serviços que possam ser impactados. Validar se o tempo de resposta aumenta, se a quantidade de erros aumenta, etc. Nesse ponto é muito importante o bom uso da observabilidade para de fato ter a visão do que acontece com os serviços.
Analisar resultados: Baseado na observação é necessário analisar as informações e entender se existe um ponto de melhoria ou alguma alteração necessária.
Aplicar os aprendizados: Aplicar as ações de melhoria levantadas durantes os testes.
Como implementar (Prática)#
Para realizar os testes iremos utilizar a ferramenta Chaos Mesh e instalaremos ela utilizando o helm. Primeiro iremos adicionar o repositório:
helm repo add chaos-mesh https://charts.chaos-mesh.org
Criaremos o namespace:
kubectl create ns chaos-mesh
E instalaremos o Helm:
helm install chaos-mesh chaos-mesh/chaos-mesh -n=chaos-mesh --set controllerManager.leaderElection.enabled=false
Para aplicar os testes podemos utilizar a interface gráfica que a ferramenta disponibiliza ou utilizando os artefatos do kubernetes. Para acessar o dashboard, onde poderemos executar os testes, utilizaremos o port forward:
kubectl port-forward -n chaos-mesh svc/chaos-dashboard 2333:2333
Acessando o dashboard no endereço http://localhost:2333 teremos acesso para criar e visualizar os experimentos, dentre outras opções.
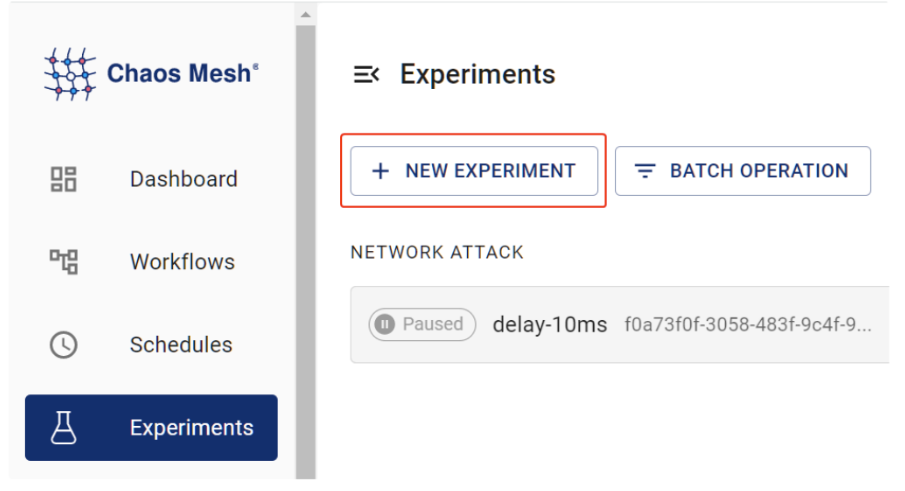
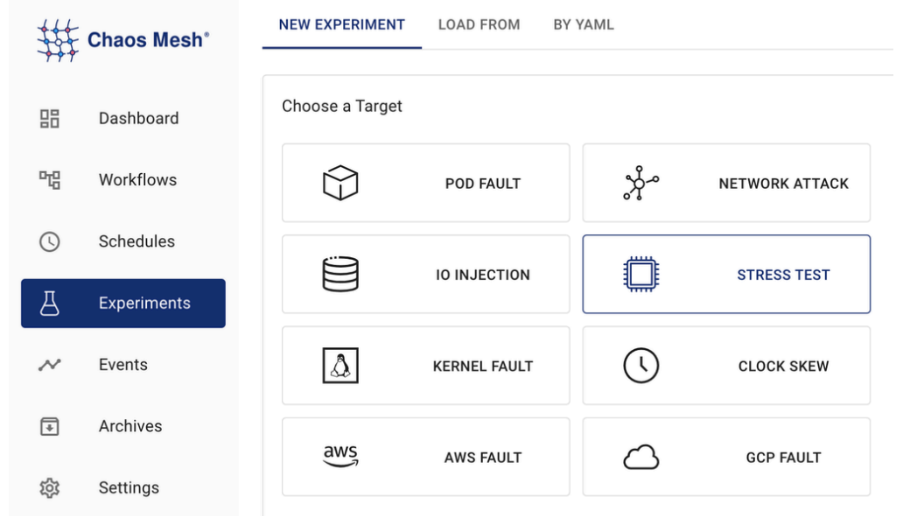
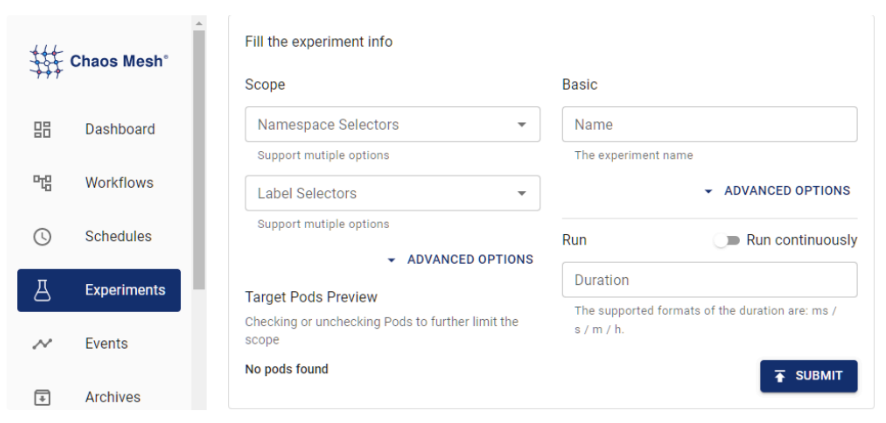
Como dito anteriormente também podemos realizar os experimentos via manifesto, aqui deixo alguns exemplos:
Realizar teste de stress de memória#
apiVersion: chaos-mesh.org/v1alpha1
kind: StressChaos
metadata:
name: memory-stress
namespace: default
spec:
duration: 5m
mode: one
selector:
labelSelectors:
app.kubernetes.io/name: app
namespaces:
- default
stressors:
memory:
workers: 1
size: '4GB'
Realizar teste de delay da rede adicionando um delay ao pod#
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: network-delay
namespace: default
spec:
duration: 5m
action: delay
mode: all
selector:
labelSelectors:
app.kubernetes.io/name: app
namespaces:
- hom7
delay:
latency: '100ms'
correlation: '100'
jitter: '0ms'
Realizar um teste de pod com falha:#
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-failure
namespace: default
spec:
action: pod-failure
mode: one
duration: '30s'
selector:
labelSelectors:
app.kubernetes.io/name: app
namespaces:
- default
Como dito anteriormente é muito importante que a estrutura de observabilidade esteja em dia para acompanhar o que acontece com o ambiente testado. Inclusive o teste de engenharia do caos pode servir para testar sua observabilidade também, validar se os alertas são ativados corretamente, se escalonamento automático funciona como deveria e por aí vai. E claro, sempre importante que se gere um resultado sobre o teste e caso o resultado não seja bom, que medidas para melhoria sejam tomadas.